
 繁体
繁体
第29章(2/2)
台上的青年双手撑在台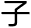 上,就从容地这样看着底下所有的人激烈地议论着。
上,就从容地这样看着底下所有的人激烈地议论着。
今天用作话cue一下半截小天使qaq宝,应该是审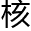 老师以为你在说我,所以删掉了评论!我是
老师以为你在说我,所以删掉了评论!我是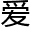 你的啊啊啊!谢谢你的评论!
你的啊啊啊!谢谢你的评论!
数据集成,顾名思义就是将大量的数据堆积传输给人工智能,试图让人工智能通过无穷无尽的数据去逐步理解人类的情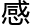 和意识,从而达到最终的全知全能,拥有自主意识。
和意识,从而达到最终的全知全能,拥有自主意识。
在这样的研究之下,最终人类还是倾向于第一条研究方向,并且展开了将近三百年的研究。
收藏评论的小可们呢,比心!!!!
第15章 锋芒毕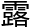
而另一条思路,仿人类思维诞构,则是另外一个截然不同的理论。
所有的人都在你一言我一语地低声说着什么,所有人的 中都盛满了质疑。
中都盛满了质疑。
可以说在现在,通过这个思路,仿生人的言语和行为都已经相当接近人类了。
这一派的议论认为,并不是给予人工智能越多的信息,他就会越接近人类。
这个思路听起来好像非常可行,但是人类最终却失败了。
通过快速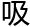 收人类的知识、想法、行为,人工智能可以
收人类的知识、想法、行为,人工智能可以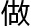 到无限
到无限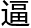 近人类的角
近人类的角 ,他能够很好地
,他能够很好地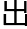 善恶的判断,也能够完全符合人类的理解。
善恶的判断,也能够完全符合人类的理解。
在场的学者们不知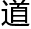 在台上的人
在台上的人 行发表时就这样不停地议论是一件非常失礼的事情吗?
行发表时就这样不停地议论是一件非常失礼的事情吗?
不论是夸奖还是批评的评论,我都不会删掉的!这都是大家的心意,非常谢!!!鞠躬!
一个冰冷的机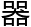 ,再怎么样去学习,似乎也无法成为人类。
,再怎么样去学习,似乎也无法成为人类。
事实证明,这似乎也的确是一条正确的路径,就在陈明霖开场时就能看,在现在的升级版图灵测试中,新模型已经有了极佳的表现。
原因也很简单,因为人工智能作为机械产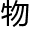 ,其模型本
,其模型本 就是由大量数据搭建起来的,不论再怎么行模仿,他们的脑中都储存着无限的数据。
就是由大量数据搭建起来的,不论再怎么行模仿,他们的脑中都储存着无限的数据。
不,他们当然清楚,但是此时的他们已经顾不上礼节了。
仿生人自主意识的产生主要有两条研究方向,其中一条,就是目前主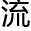 一直在使用的数据集成思路,另一条则是没有多少人选择尝试的仿人类思维诞构思路。
一直在使用的数据集成思路,另一条则是没有多少人选择尝试的仿人类思维诞构思路。
这一条思路是目前最为主的思路,已经沿用了两百余年。而选择这条路径的原因其实非常简单,就是因为它在目前有着最佳的成效。
相反,他们认为应该给人工智能制造一个类似于人类的大脑,然后在一个完全模仿人类成长的环境让这个人工智能长大,他所接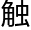 和收的所有信息都要无限接近于人类,最终就会得到一个拥有人类思维的仿生人。
和收的所有信息都要无限接近于人类,最终就会得到一个拥有人类思维的仿生人。
